Transformer
为何Transformer?
在Attention一节中,我们讲述了注意力机制为循环神经网络带来的优点。那么有没有一种网络直接基于注意力机制进行构造,而不再依赖RNN呢?该网络结构就是Transformer!
Transformer模型在2017年google提出,直接基于Self-Attention结构,取代了之前NLP任务中常用的RNN结构。
与RNN这类神经网络结构相比,Transformer一个巨大的优点是:模型在处理序列输入时,可以对整个序列输入进行并行计算,不需要按照时间步循环递归处理输入序列。
Transformer宏观结构
以机器翻译为例,来讲解Transformer这种特殊的Seq2Seq模型。
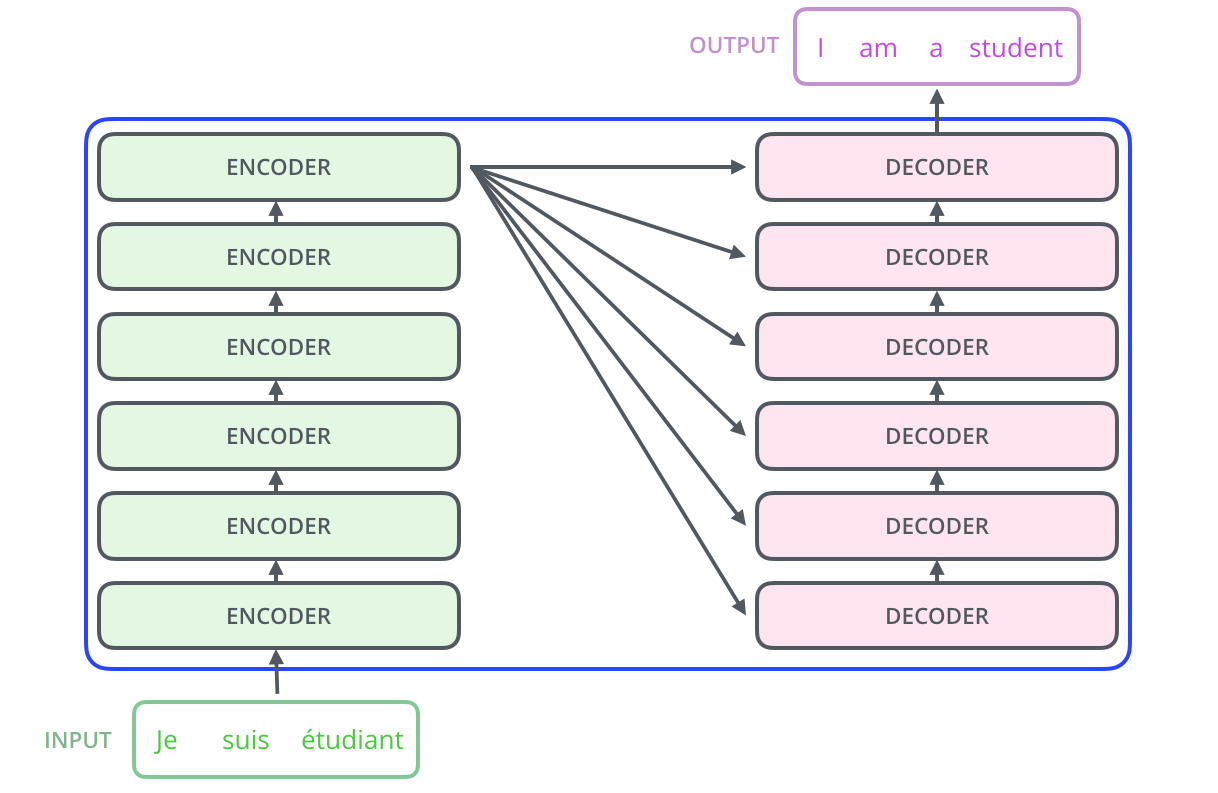
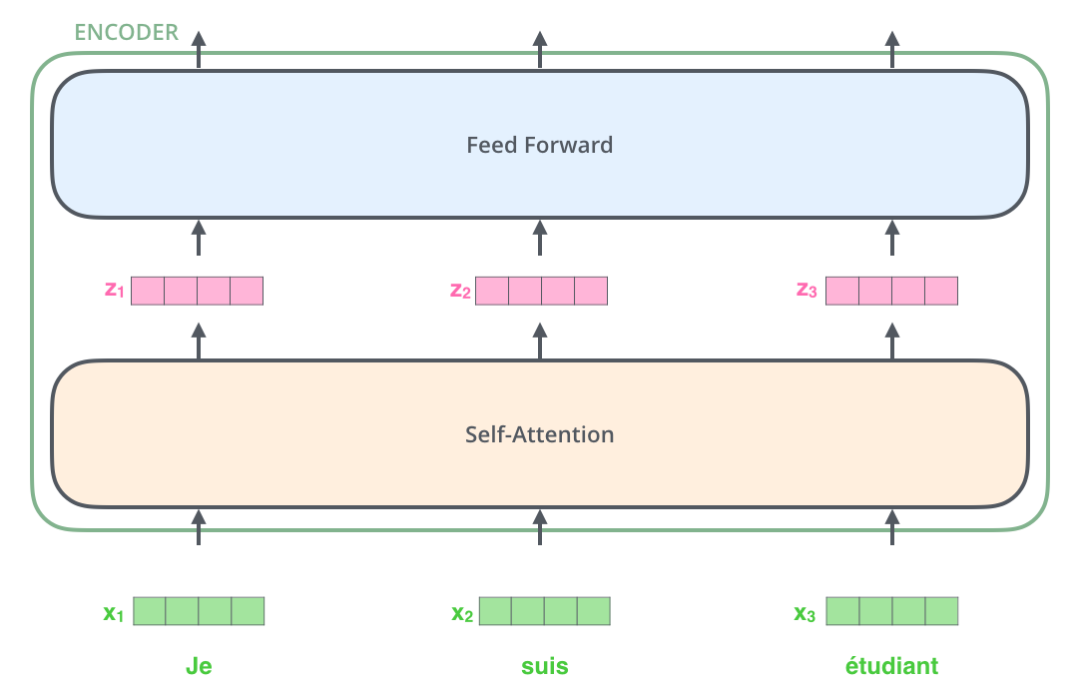
我们可以看到,Transformer由编码部分和解码部分组成,其中编码部分由6层编码器堆叠而成,解码器由6个解码器组成。每层编码器和解码器的结构是一样的,不同编码器和解码器网络结构不共享参数。
编码器
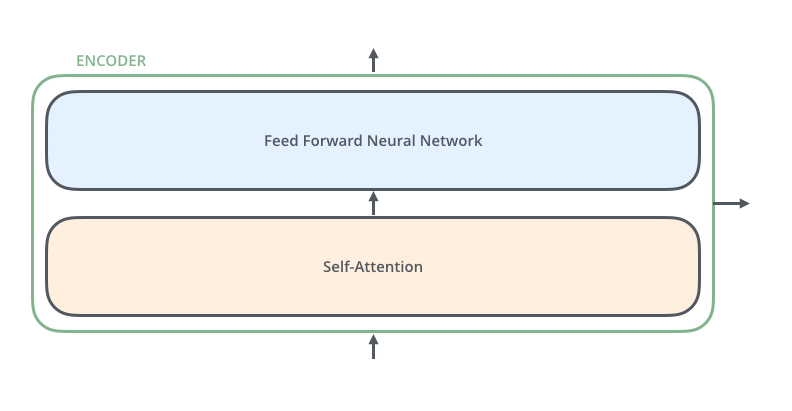
单层encoder由以下两部分组成: 1. Self-Attention层 2. Feed Forward Neural Network 前馈神经网络
编码器的输入文本序列\(\{w_1,w_2,...,w_n\}\)最开始需要经过embedding转换,得到每个单词的向量,将文本序列转换为向量序列\(\{x_1,x_2,...,x_n\}\),其中\(x_i\)使一个维度为\(d\)的向量。所有向量经过Self-Attention神经网络层进行编码和信息交互得到\(\{h_1,h_2,...,h_n\}\)。Self-Attention层在处理每一个词向量的时候,不仅会使用这个词本身的信息,也会使用句子中其他词的信息。
Self-Attention层的输出会经过前馈神经网络得到新的\(\{x_1, x_2,..,x_n\}\),依旧是\(n\)个维度为\(d\)的向量。这些向量将被送入下一层encoder,继续相同的操作。
解码器
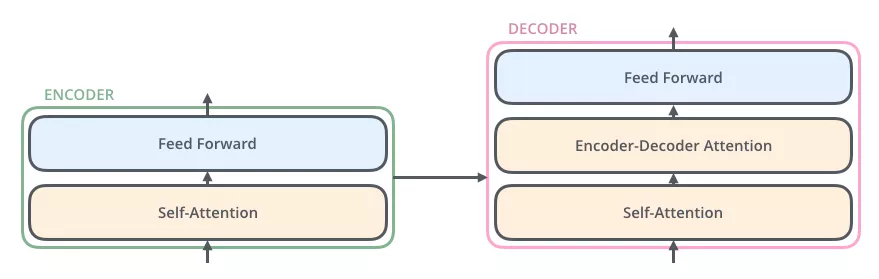
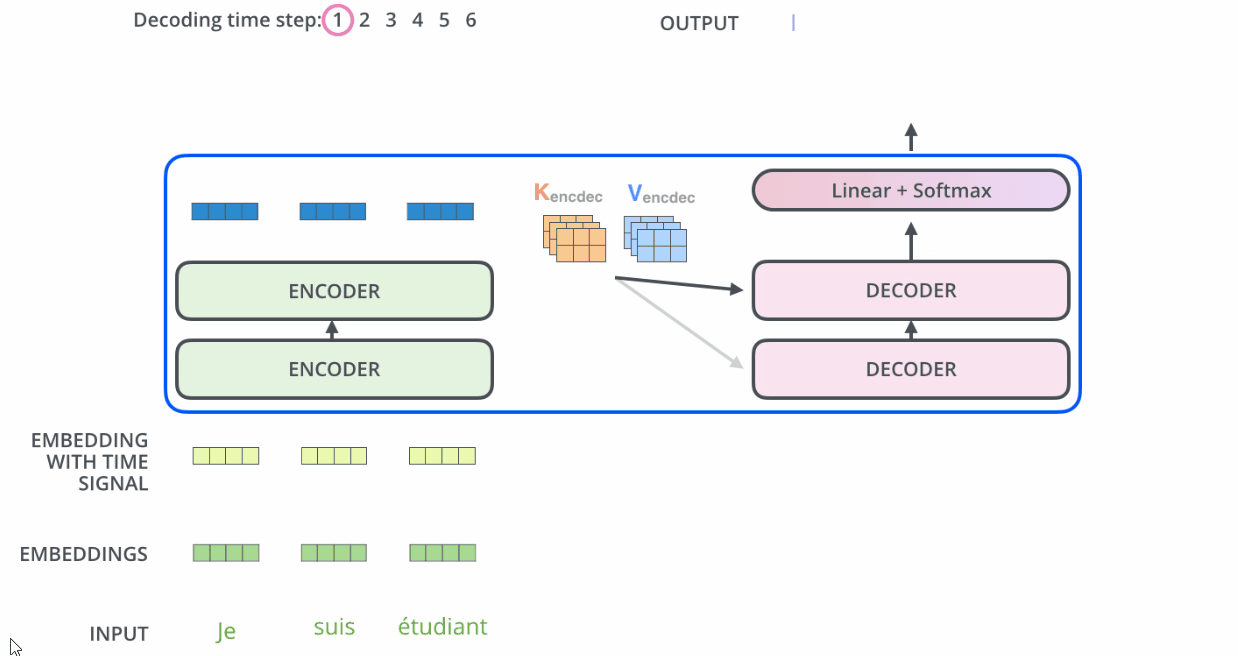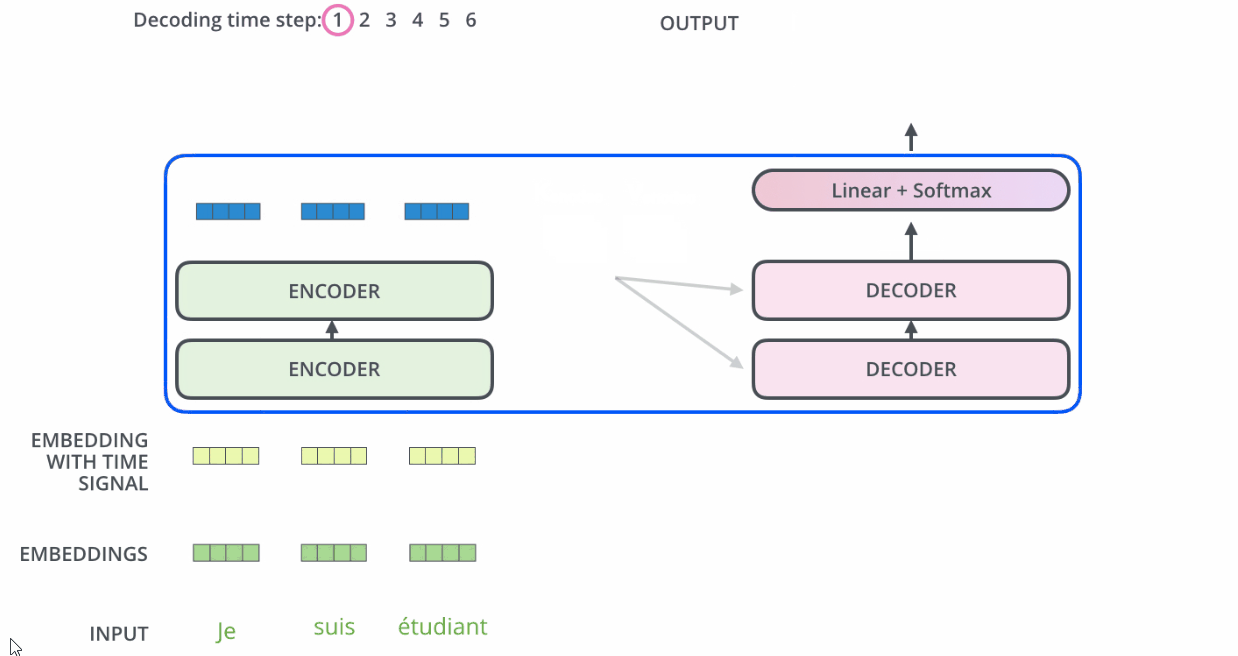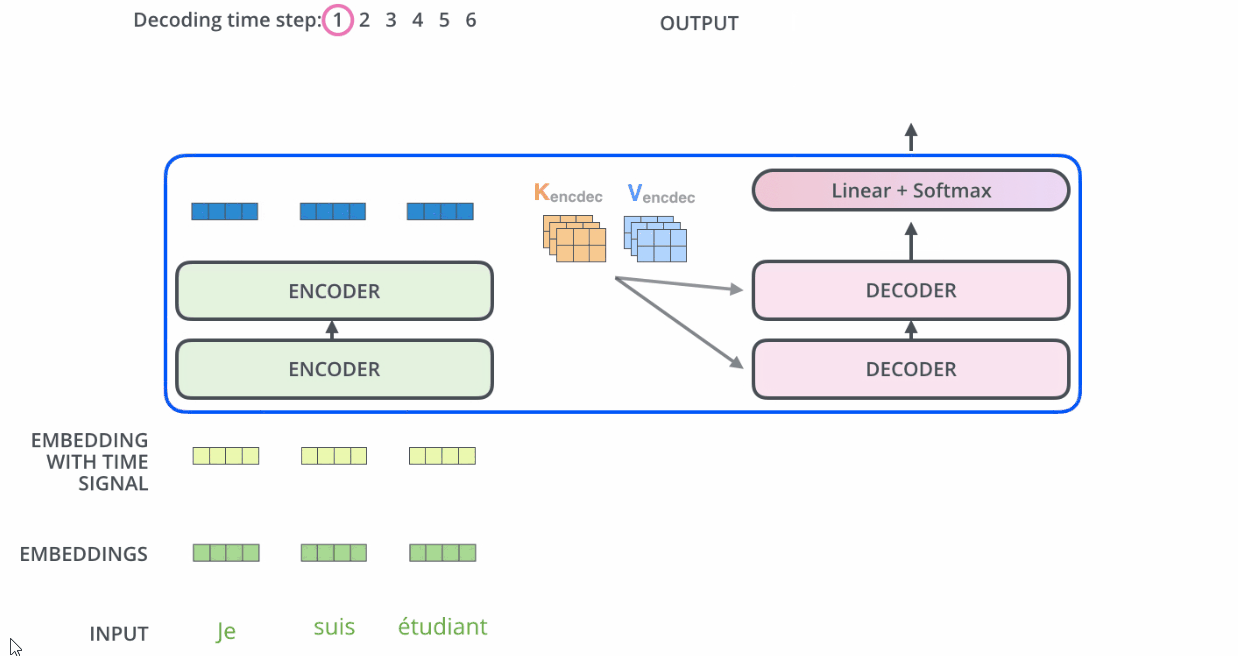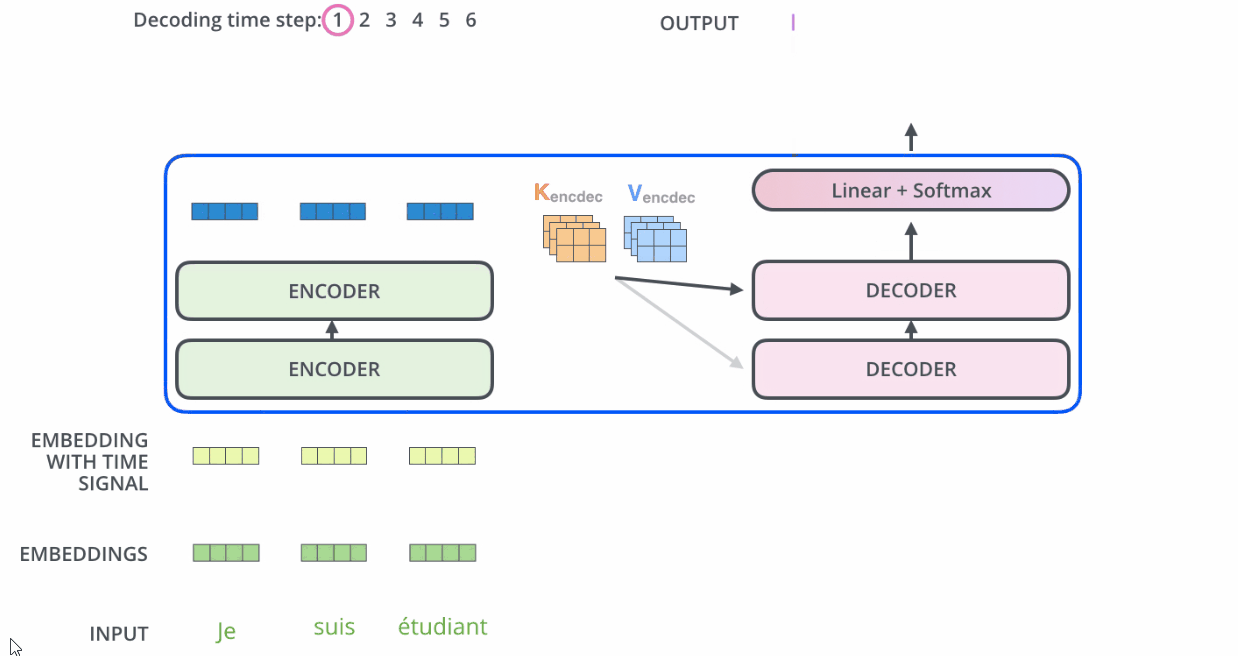
与编码器对应,如下图,解码器在编码器的self-attention和FFNN中间插入了一个Encoder-Decoder Attention层,这个层帮助解码器聚焦于输入序列最相关的部分。
Transformer结构细节
输入处理
词向量
和常见的NLP任务一样,我们首先会用词嵌入算法,将输入文本序列中的每一个词转换为词向量。实际中词向量一般为256维或者512维,这里我们使用4维词向量表示。
如下图,假设我们的输入文本包含了3个词,那么每个词可以通过词嵌入算法得到一个4维向量,于是整个输入被转换为一个向量序列。

在实际应用中,我们通常会给模型输入多个句子,如果每个句子的长度不一样,我们会选择一个合适的长度,作为输入文本的最大长度。如果句子达不到长度,那么就先填充特殊字符[padding],如果句子超出这个长度,则做截断。
位置向量
输入序列每个单词被转换为词向量表示还加上位置向量来表示该词的最终向量表示。
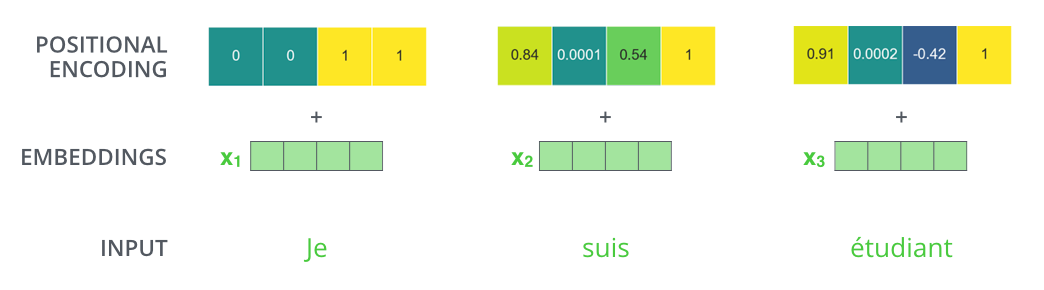
Transformer模型对每个输入的词向量都加上了一个位置向量,可以得到新向量。新向量有助于确定每个单词的位置特征,或者句子中不同单词之间的距离特征,可以为模型提供更多有意义的信息。
那么如何编码呢?
\[ PE_{(pos,2i)} = sin(pos / 10000^{2i/d}) \]
\[ PE_{(pos,2i+1)} = cos(pos / 10000^{2i/d}) \]
上面表达式中的\(pos\)表示词的位置,\(d\)表示位置向量的维度,\(i\)表示位置向量的第\(i\)维(\(1 \leq i \leq d\))
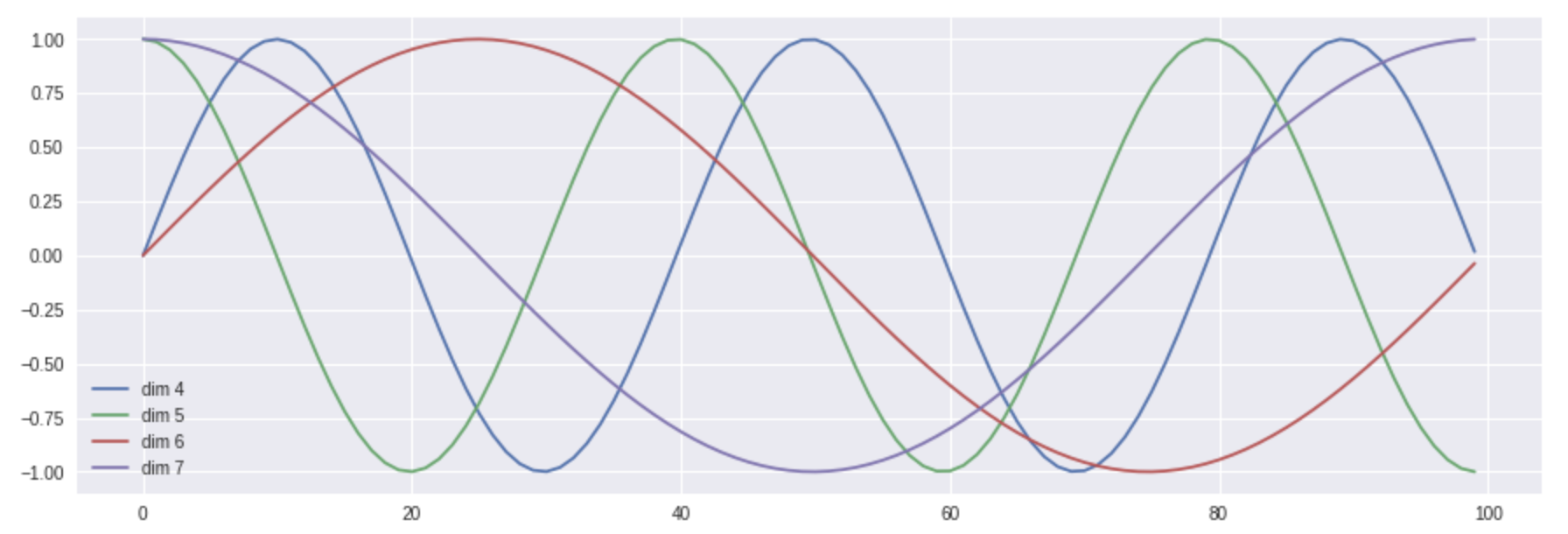
上图为100词,词向量的第4-7维的位置编码图像。
Encoder
文本序列经过输入处理之后得到了一个向量序列,这个向量序列将被送入编码器。
下面展示了向量序列进入Encoder编码器的过程。
Self-Attention
The animal didn't cross the street because it was too tired
这个句子中的 it 是一个指代词,那么 it 指的是什么呢?它是指 animal 还是street?
引入Self-Attention机制能够让模型把it和animal关联起来。同样的,当模型处理句子中其他词时,Self Attention机制也可以使得模型不仅仅关注当前位置的词,还会关注句子中其他位置的相关的词,进而可以更好地理解当前位置的词。
下面我们将更加详细的介绍自注意力机制。
假设一句话包含两个单词:Thinking Machines。自注意力的一种理解是:Thinking-Thinking,Thinking-Machines,Machines-Thinking,Machines-Machines,共\(2^2\)种两-两attention。
我们通过以下6个步骤,进行自注意力计算:
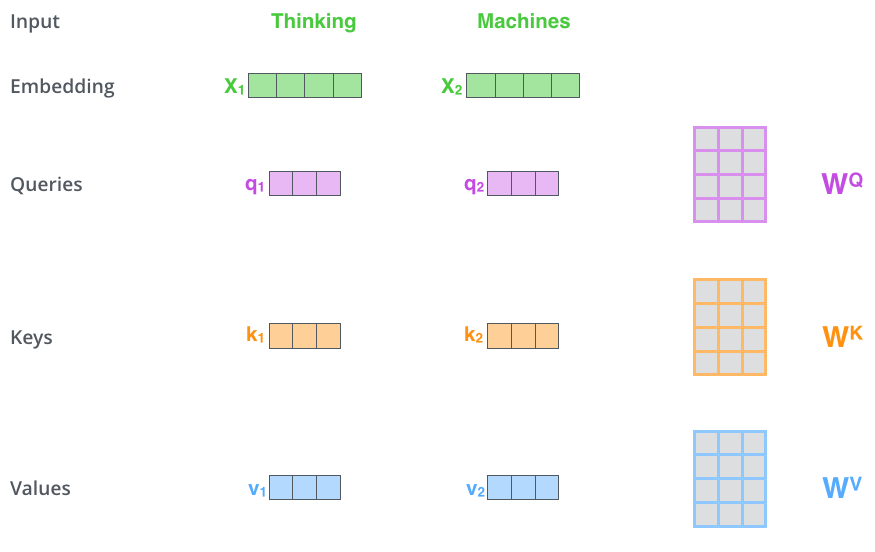
线性变换,计算query向量:Query向量: \(q_1, q_2\),Key向量: \(k_1, k_2\),Value向量: \(v_1, v_2\)。这3个向量是词向量分别和3个参数矩阵相乘得到的,而这个矩阵也是是模型要学习的参数。
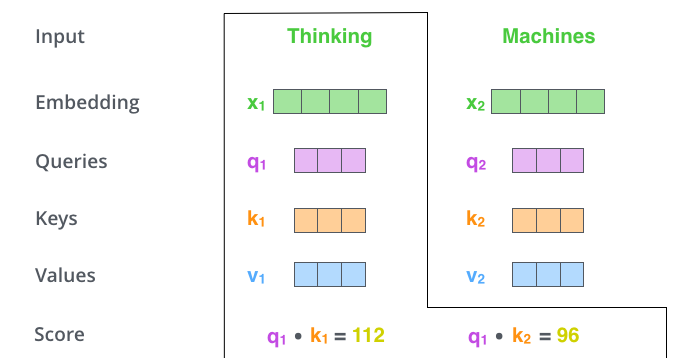
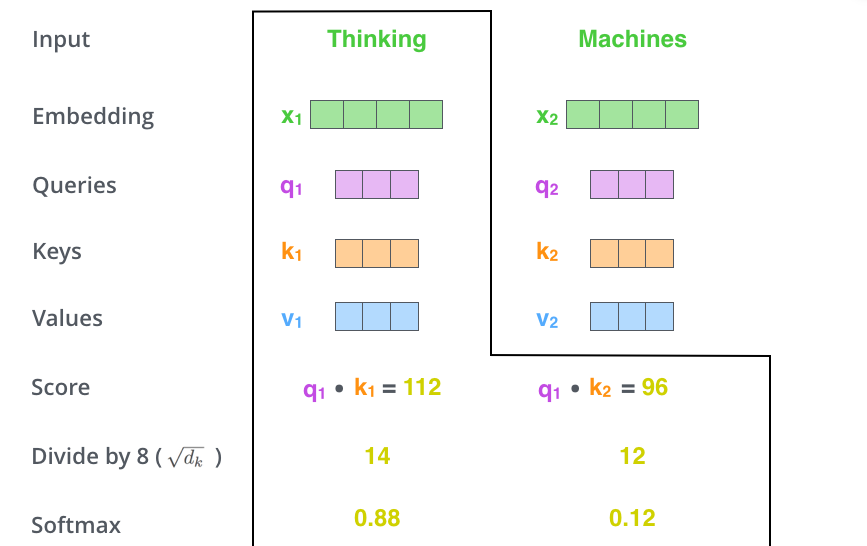
计算注意力得分:假设我们现在计算第一个词Thinking 的Attention Score(注意力分数),需要根据Thinking 对应的词向量,对句子中的其他词向量都计算一个分数。这些分数决定了我们在编码Thinking这个词时,需要对句子中其他位置的词向量的权重。
把每个分数除以 \(\sqrt{d}\),\(d\)是Key向量的维度。你也可以除以其他数,除以一个数是为了在反向传播时,求梯度时更加稳定。
归一化:接着把这些分数经过一个Softmax函数,Softmax可以将分数归一化,这样使得分数都是正数并且加起来等于1, 如下图所示。 这些分数决定了Thinking词向量,对其他所有位置的词向量分别有多少的注意力。
分数xValue:得到每个词向量的分数后,将分数分别与对应的Value向量相乘。这种做法背后的直觉理解就是:对于分数高的位置,相乘后的值就越大,我们把更多的注意力放到了它们身上;对于分数低的位置,相乘后的值就越小,这些位置的词可能是相关性不大的。
求和:把第5步得到的Value向量相加,就得到了Self Attention在当前位置(这里的例子是第1个位置)对应的输出。
通过以上6步,我们可以最终得出Thinking的注意力输出,这个过程中Thinking的注意力同时注意到了Thinking-Thinking,Thinking-Machines。
多头注意力机制
Transformer 的论文通过增加多头注意力机制,进一步完善了Self-Attention。这种机制从如下两个方面增强了attention层的能力。
- 它扩展了模型关注不同位置的能力
- 多头注意力机制赋予attention层多个“子表示空间”
经过以下3个步骤,可以计算多头注意力:
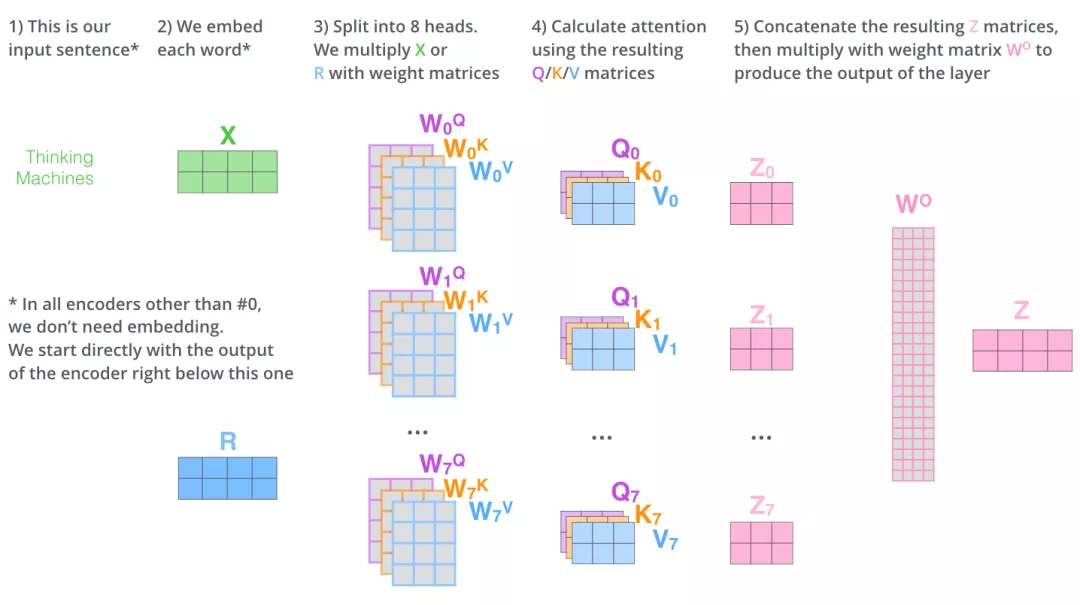
多头注意力机制会有多组\(W^Q,W^K,W^V\)的权重矩阵。每一组注意力的权重矩阵都是随机初始化的,但经过训练之后,每一组注意力的权重\(W^Q,W^K,W^V\)可以把输入的向量映射到一个对应的“子表示空间”。以下图片有2组Q、K、V。

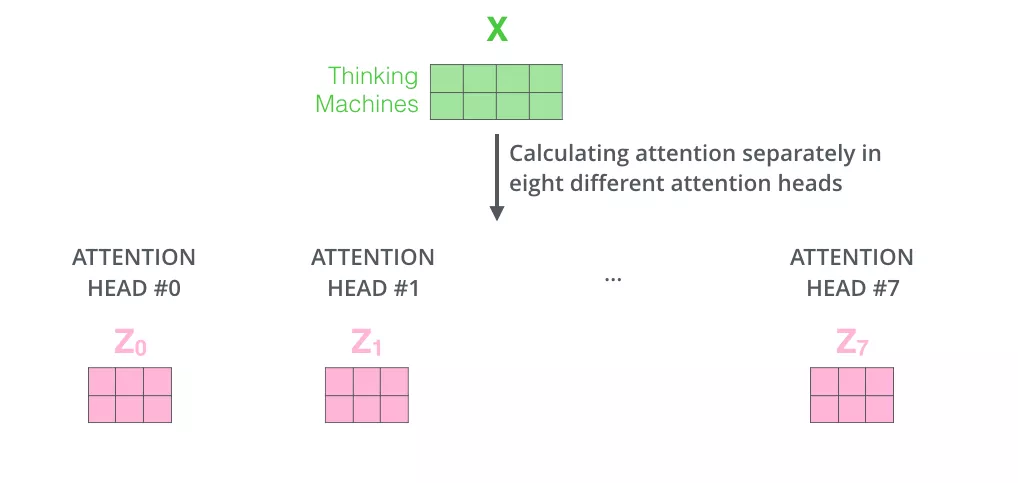
计算多组Z矩阵。(在 Transformer 的论文中,使用了 8 组注意力)
拼接所有Z矩阵,所以我们直接把8个子矩阵拼接起来得到一个大的矩阵,然后和另一个权重矩阵\(W^O\)相乘做一次变换,映射到前馈神经网络层所需要的维度。这个矩阵会输入到FFNN (Feed Forward Neural Network)层。
Encoder总结
Decoder
Self-Attention 和 RNN的区别
- RNN 在处理序列中的一个词时,会考虑句子前面的词传过来的hidden state,而hidden state就包含了前面的词的信息。
- 而Self Attention机制值得是,当前词会直接关注到自己句子中前后相关的所有词语。